TL;DR
-----
*Over the last several days, the Riot Esports Tech Team has been working through a set of technical issues surrounding a tool we are using to equalize the ping values between our local and remote competitors for the Mid-Season Invitational 2022 (MSI) event.
The first issue was a bug that we found in software called the Latency Service Tool, which was configured to adjust the latency (ping) to 35 ms for all players competing in the event. The bug manifested as excess ping for players in the venue in Busan, Korea: their actual ping was higher than the 35 ms that was displayed on their screens. In effect, while the players in China were playing with 35 ms ping, the ping for the players in Busan was higher. Unfortunately, the issue was not discovered before the start of the event. The reason we did not find it sooner is that the cause of the issue was a code bug that miscalculated latency, which meant that the values in our logs were also wrong. As a result, our ongoing monitoring and pre-event testing showed everything was working correctly, even though it was not.
We were able to apply a configuration change to the Latency Service Tool on May 13th to address the bug. Given that the networking environment disadvantaged players in the Busan venue by applying excess latency, we made the difficult but necessary decision to replay the three Group B games where the ping levels were not at parity.
A side effect of the May 13th fix was a visual issue where the ping displayed on players’ screens in Busan was incorrect as it was lower than the actual, corrected ping. As a result, when we broadcasted a player’s screen, we showed this incorrectly lower ping value, and, because we had not proactively communicated this visual discrepancy, viewers understandably believed that players in the venue were playing on lower ping than they actually were.
This post walks through these issues from a technical perspective from pre-event through present (post-Groups).*
Pre-Event
---------
As we started planning the last mile of our tech setup for this year’s MSI event, we were presented with ongoing COVID-19 related challenges. The LPL team representative, Royal Never Give Up (RNG), was unable to travel from Shanghai to Busan and would compete remotely.
On the surface, the easy solution would be to have the remote team connect to the MSI shard while local teams are playing on the LAN. However, there are several issues that make this option undesirable.
One problem is that Busan and Shanghai are approximately 850 kilometers (km) away from each other (with the Yellow Sea between them). This means that network traffic has to hop around as it travels between Shanghai and the MSI competition servers in Korea, and then back again to Shanghai.
This round trip network traffic timing is measured as “ping” (a.k.a latency). From RNG’s location to the MSI competition servers, it clocks in at about 35 milliseconds (ms). Ten of the eleven teams are located on site at the Busan venue, and their ping is lower, at around 15 ms. Note that these ping values are approximate because they naturally fluctuate +/- 5ms.
For the average League of Legends player, the difference between 35 ms ping and 15 ms ping may not be noticeable, but for professional players, this changes the feel of the game enough to make a small but noticeable difference. Because one of our core principles is competitive integrity, we need to ensure that all teams compete on a level playing field during our tournaments.
To get a level playing field, we needed to address the issues of ping disparity.
Making remote play competitively viable
---------------------------------------
Because esports matches are played over a network, we pushed forward on exploring a remote solution for MSI 2022.
The two questions were:
- Is the 35 ms ping between Shanghai and Busan within the tolerance to enable competitive skill expression at the highest level?
- Could we provide a way to have a level playing field so that all players experienced the same latency?
The answer to #1 was “yes.” For League of Legends Esports, we have a ceiling of 40 ms for play to be considered viable at the highest competitive level with an acceptable variance of +/- 5 ms. This number was decided on in mid 2020 through deep discussion and analysis with both internal and external partners, as well as our internal Game Analysis and Design group. 40 ms is the inflection point where the majority of the consulted players begin to notice the ping, and it begins to affect things such as draft picks, landing skillshots, and ability to make snap reactions to opponents’ plays.
To answer #2, we considered our options:
**Option 1: Each team plays with the natural network latency that they have**
This option consists of having the remote teams connect to the MSI competition servers using the fastest possible internet at their disposal. This would mean that teams at the MSI venue could play on very low ping (~15 ms), while the remote team (RNG in this case) would get whatever their natural latency is (~35 ms in China).
We reviewed and rejected this option based on our principle of competitive integrity as we want to ensure parity for all teams.
**Option 2: Put the servers halfway between China and Korea**
If we have 35 ms ping between China and Korea, another option would be to place servers in the middle, splitting the difference in ping, so everyone has 17.5 ms ping. There are a lot of challenges with this option… but the biggest, of course, is that this would place the servers in the middle of the ocean.
**Option 3: Introduce artificial latency**
So if the problem is that teams competing in Korea have very low ping, and the teams in China have a higher ping, what if we add some delay on the Korea side to equalize? Would this work? Can we do this?
It turns out that the League Dev Team already has a way to introduce artificial latency, known as the Latency Service. Some refer to it as “fake ping.” This is a client/server feature that was built to address the need to level the playing field for remote competition due to COVID-19 travel restrictions. The Latency Service allows us to set a target (say 35 ms ping), and it injects delay on the client and server for each player as needed to equalize everyone at that same level of latency.
While the Latency Service had been used before for esports events, those events were fully remote, and this would be the first time we would be using it to introduce latency for a global event, where some teams were in a local venue. So while we have used it before, there is always a chance that some subtle difference in the environment would bring out a bug that we didn’t see otherwise. By enabling the artificial latency in the scrim servers and running our usual infrastructure and network testing, we believed we would have enough real-world usage to find any major issues before the start of Groups.
**Our Choice**
Weighing our options, we decided that the most important thing was to strive for competitive fairness, and thus artificial latency would be the best path forward.
Exploring artificial latency: How it works
------------------------------------------
The Latency Service is built into the native client/server networking stack of the League of Legends software. It continuously measures the actual network latency between each player and the server, making adjustments as needed by adding delay with the goal of hitting the target latency value. It is a client/server solution, so it seeks to introduce this delay on both sides of the network equally.
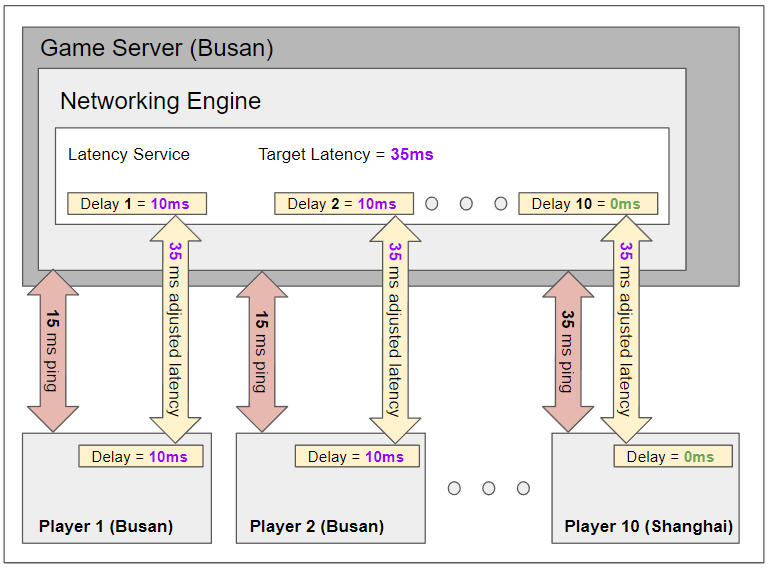
The diagram above shows the various components of the system. On the top side of the diagram, you can see the game server components and the bottom side of the diagram shows the client (the player’s PC). In this example, the Latency Service is configured to equalize at 35 ms. The red arrows in the diagram indicate the actual network latency that is present. As you can see, Player 1 and Player 2 in Busan show an “actual” ping of 15 ms, while Player 10 in Shanghai shows 35 ms ping. The yellow boxes indicate how much delay is introduced artificially on the client and server side. In this case, Player 1 and Player 2 each have 10 ms of delay added to the client side and to the server side to achieve the target of 35 ms. Player 10 already has real latency that is equal to the target latency of 35 ms and thus has no delay added (0ms).
One level playing field or two level playing fields?
----------------------------------------------------
To dive in even deeper, we should talk about a decision we made regarding the remote environment vs. the in-venue environment.
For the Esports Tech Group, we always seek to minimize risks for our live events. The memory of the 2012 Season 2 Worlds in Los Angeles where we had to cancel the event mid-day due to internet issues is burned into the psyche of every Rioter who works in esports.
When deciding on the network topology for the MSI 2022 event, we realized we had to decide between two different strategies:
**Strategy #1: One topology for all scenarios**
With our global competitive tournaments, games are played on servers that are physically present at the event venue. This gives us a high degree of reliability because it allows us to directly control the network and the server hardware. Given that one team was going to be remote, we knew we had to support the scenario where at least one team will be connecting over the internet network. So if one team would have to connect over the internet, one strategy would be to fully abandon our locally deployed servers and have all teams connect over the internet.
Given the principle of reliability, we knew if we had to have an internet-based game server, we wanted to choose a deployment in which we had the most confidence. The obvious choice for this was to use the Korea esports game servers. This is a pro-only environment that is housed in the same data center as the Korea public servers and is used regularly for LCK, our Korean league. This means we have countless player hours on it to verify that it has good network connectivity and reliable infrastructure. From a reliability perspective it is clear that when at least one team needs to be remote, using this shard makes a lot of sense. But then the question is whether we should use it for all games or just for games where one team is remote. That leads to strategy #2: minimize exposure to network risk.
**Strategy #2: Minimize exposure to network risk by using remote only as needed**
In the previous strategy, given the need for some games to be played in an internet-housed environment, the question then becomes, “Why not just play them all in that environment?” For this, there is a very simple answer: internet reliability. Maybe the internet will perform perfectly, maybe it won’t. If all MSI games are played through the internet, then any internet network issue has the potential to cause an issue in game. If only the games with remote participants are played through the internet, then we reduce the overall internet reliability risk to just those games. While we are confident in our ability to overcome internet issues through a number of contingency plans, it is still ideal to keep this risk as low as possible. Given our ability to level the playing field in terms of ping through the use of artificial latency, this was a matter of complexity vs. reliability. We have a bit more complexity (two topologies) in order to achieve lower risk (minimize exposure to potential internet reliability issues).
Given these two options, we decided to go with strategy #2 based on our assessment that this would present the lowest total risk to the reliability and competitive integrity of the event.
What you see below is a diagram of the topology that we selected. This shows the various scenarios that we have in terms of network connectivity.
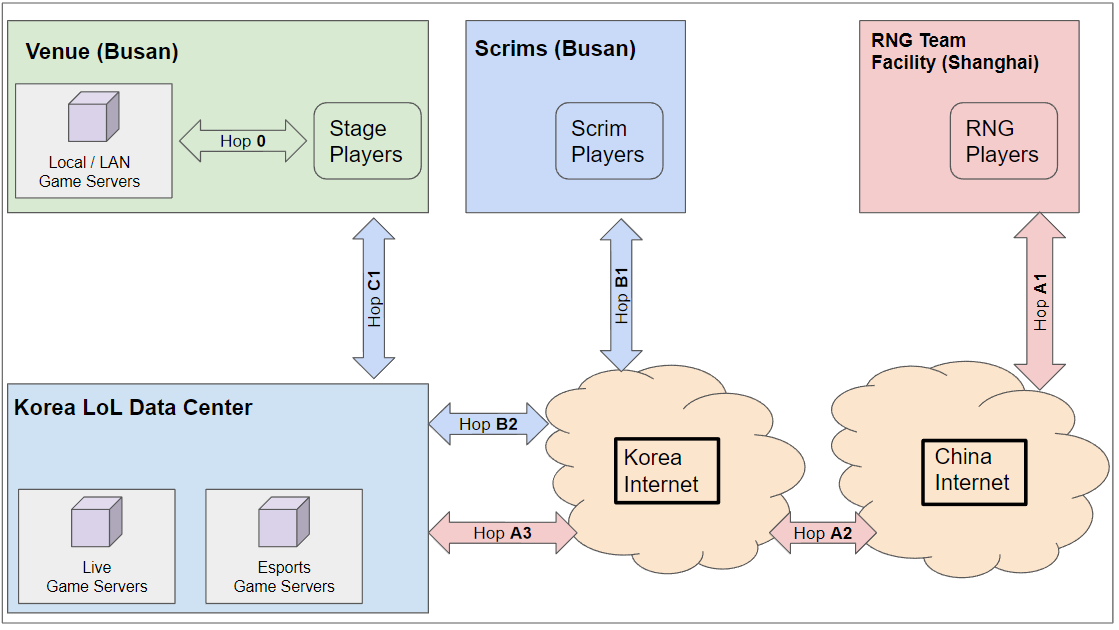
Best laid plans…
----------------
Weighing all the factors above, we made the decision to support two different topologies while maintaining competitive integrity by using the Latency Service to keep the latency level equal across all games. The games between teams physically located in Korea would be played on the game servers in the MSI venue, and the games that included the remote team would be played on the esports game servers in the Korea data center. We set up the system and performed infrastructure testing to ensure that everything was correct. This included measuring and monitoring ping, network jitter, and looking closely to see if there was any packet loss. We also had teams play scrims using the esports game servers and had them come to the arena to do tech checks on the stage.
After the first day of competition, players told us that the games felt off. Some players were reporting that even though the on-screen overlay was saying 35 ms ping, to them it felt slower. All of our logs and infrastructure monitoring tools showed that everything was correct, but we continued to investigate to pinpoint what was causing this issue.
**Chasing ghosts?**
The root cause of the issue was unclear. Our infrastructure monitoring tools were reporting no issues, and while we had reports that the ping felt high, there were no specific bugs or game situations to look through. So we went back to first principles. What data is available? What logs do we have? What information can we collect?
We took a two-pronged approach. The first was to pull together a set of questions that we could ask pro teams that might help us get closer to understanding what was going on. Where did you see this? Was it worse on the venue servers or esports game servers? Was it worse on the venue network or scrim network? Was it in all games or just some games? Second, in parallel, since our standard reports were not showing anything wrong, we started proactively looking at other logs and metrics to see if there were any discrepancies. We started pulling client and server logs from the tournament and started diving into the data.
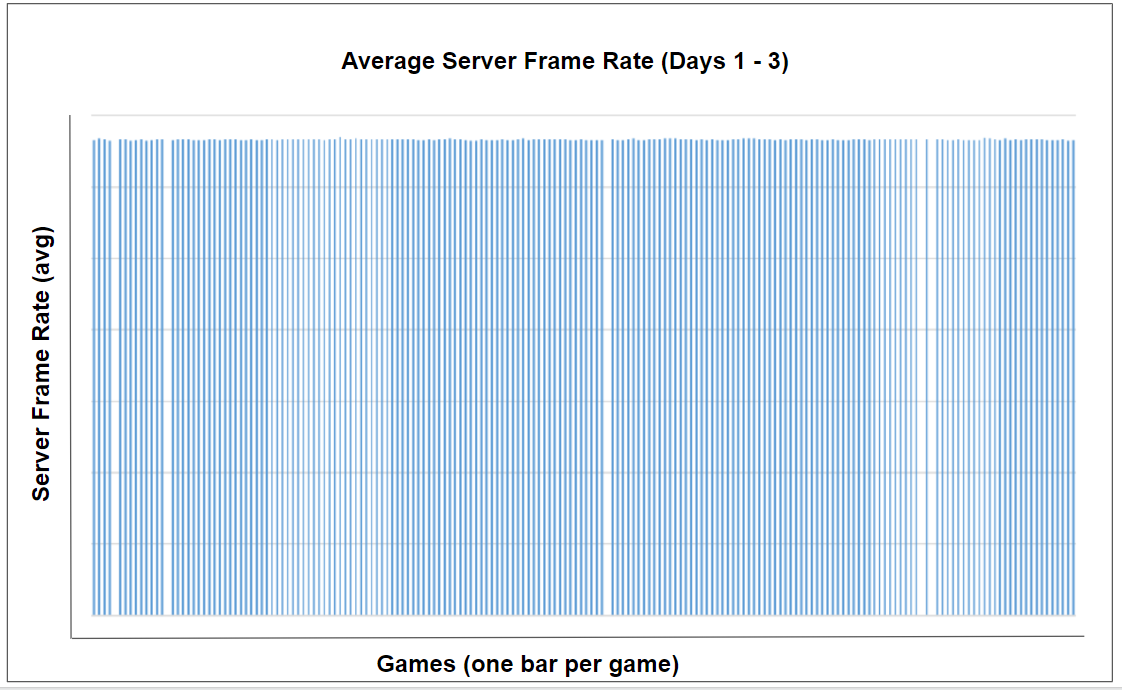
As an example, one hypothesis that we had was that maybe the game server was not keeping a steady frame rate. So we scraped the logs from all the games for the first few days and put the data into a viewing tool to visualize the data into the graph above. What this showed is that we had consistent frame rates on the server from one game to the next. The data indicated that the game server performance was stable, so it was not likely to be the cause of the inconsistent responsiveness that was reported by the pros.
Looking through logs is meticulous work. The data itself looks like pages and pages of seemingly random streams of numbers and has to be compiled through various tools in order to visualize and make sense of it. At every turn, everything we looked at showed normal results.
As we were looking through the logs and the code, we started to receive additional information back from the pro teams. There were more complaints about the MSI venue environment. This seemed counterintuitive to us. After all, the venue environment games were being played on hardware that was in the same building as the players. How could games with a perfectly controlled network environment feel worse than games that were being played over the internet?
This led to another hypothesis… If the logs show good latency measurements, but the experience was off, maybe there is something wrong with the logs? Maybe there was an issue with the way we were measuring latency?
To test this, the dev team wrote some code and compiled a custom debug build of the client. Ordinarily, the logs are generated based on the “round trip” of the game data packets between the networking layer on the server and the networking layer in the client. These logs did not show any errors. So the new tool tested the latency in a different way. Instead of testing the latency of the traffic at the network layer, we wanted to test the entire end-to-end loop from a user click all the way through seeing the response of that click. In other words, not just measuring the performance of the network, but measuring the interaction between all the systems in the game engine.
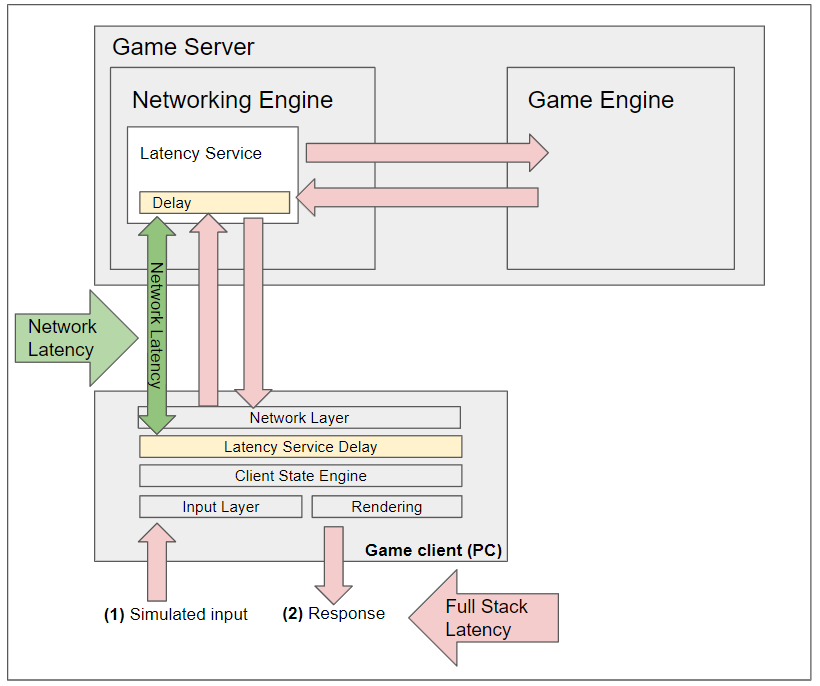
The diagram above illustrates this concept. The existing network monitoring system measured the latency at the networking layer as shown by the green arrow. As you can see, it measures everything between the networking layer and the Latency Service delay. The updated monitoring tool measures latency along the red arrows. This includes everything from the input layer through the networking layer to the game engine on the server and then back again to the client.
Now that we had a new diagnostic measuring tool, we wanted to set up some experiments in the lab to see if we could replicate the issue being reported by the players.
The first thing we wanted to do was to get a baseline measurement with the Latency Service disabled. Since we have countless player hours of data from our public servers, this was considered our “control” test where we could feel confident that we did not have any server bugs. This first experiment, which was the baseline, simulates the environment that we would have if the teams in Korea and the team in China were all connected to the server via the internet.
**Experiment 1: Latency Service DISABLED, compare Korea network to China network**
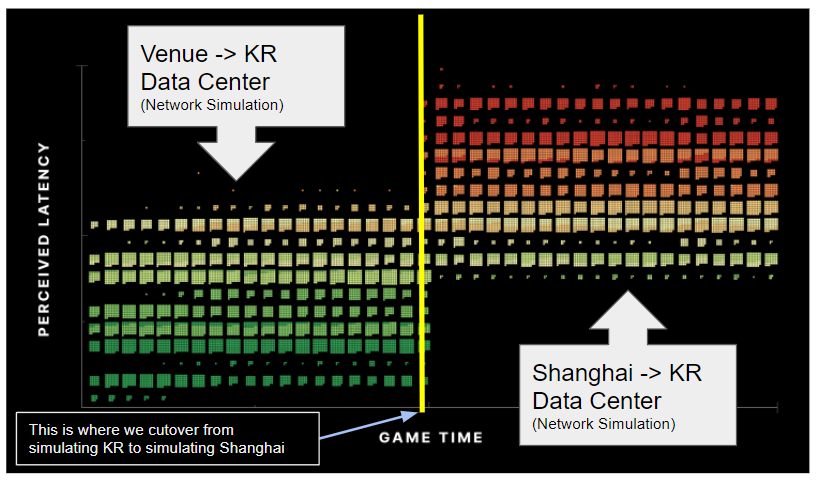
The data for these experiments are complicated, but we were able to put it together into a visual representation so we could start to understand what we were seeing.
If you follow along on the X axis (Game Time) you can see that initially (left side of the chart) the latency values were low. After a few minutes (middle of the chart from left to right), we started simulating a higher ping network (e.g. from Shanghai). As you can see, the latency measurement on the vertical axis shifted upwards. This is exactly what we would expect. On a low ping network, the latency is low, and on a higher ping network the latency is higher.
The first set of tests, the control, showed us that our measurements using the new technique were in line with our expectations. That is a good first step.
In the next experiment, we wanted to run the same tests, simulating the same networking conditions, but this time running them with the Latency Service enabled.
**Experiment 2: Latency Service ENABLED, compare Korea network to China network**
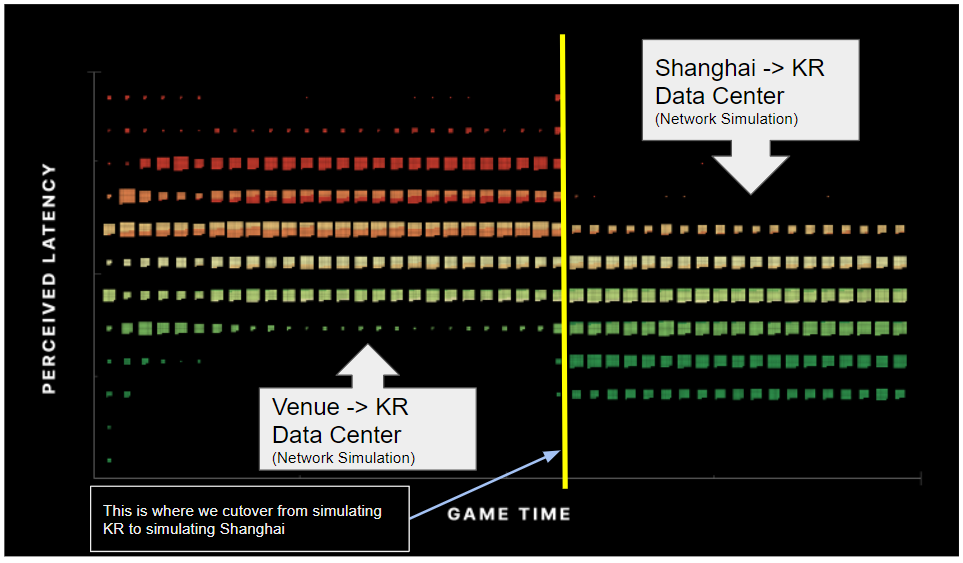
Remember that the purpose of the Latency Service is to equalize latency regardless of the natural network ping. If we changed the network ping characteristics in the lab, the expectation would be that the Latency Service would compensate and thus the latency measurements should stay the same. However, that is not what the data showed us. As you can see, the data showed that the latency measurements were lower in the Shanghai network simulation than they were for the KR network simulation. This was unexpected and shows that the Latency Service is producing a higher latency for the Korea environment than for the Shanghai environment.
From this report, we were able to determine three things:
- There is a real problem, and the new data matched what players were reporting
- We can reproduce the problem in our lab
- The problem likely has something to do with our artificial latency tool
Armed with this information, we had a very good signal as to where in the code to look for the problem. After running a variety of additional testing to see what happened when we altered the characteristics of the lab environment, we realized that there was a calculation error that only manifested in scenarios where the actual ping was significantly lower than the target latency. In this situation the actual latency would be considerably higher than what is displayed on the overlay on the player's screens.
This explained a variety of issues we were experiencing. Our logs were not displaying the issue because the calculation was wrong. It explained why the latency was worse in the venue than on the internet servers because the bug shows up worse in lower ping environments. It also explained why the players in Busan felt that the ping was worse than 35 ms *because it actually **was** worse than the 35 ms ping that was shown on their screen.*
Now that we had identified the issue, our next step was to fix it as quickly as possible.
Fortunately, by looking through the code, we were able to understand the nature of the problem and find a solution to compensate for the calculation error.
Since we had a way to simulate the environment, and a way to measure the actual latency using our custom tool, we were able to adjust the configuration settings until the latency was correctly equalized across both networks.
Below is the chart showing the same network simulations as the previous two experiments, but this time with an updated configuration that compensated for the bug in the Latency Service.
**Experiment 3: Latency Service ENABLED with corrected configuration settings**
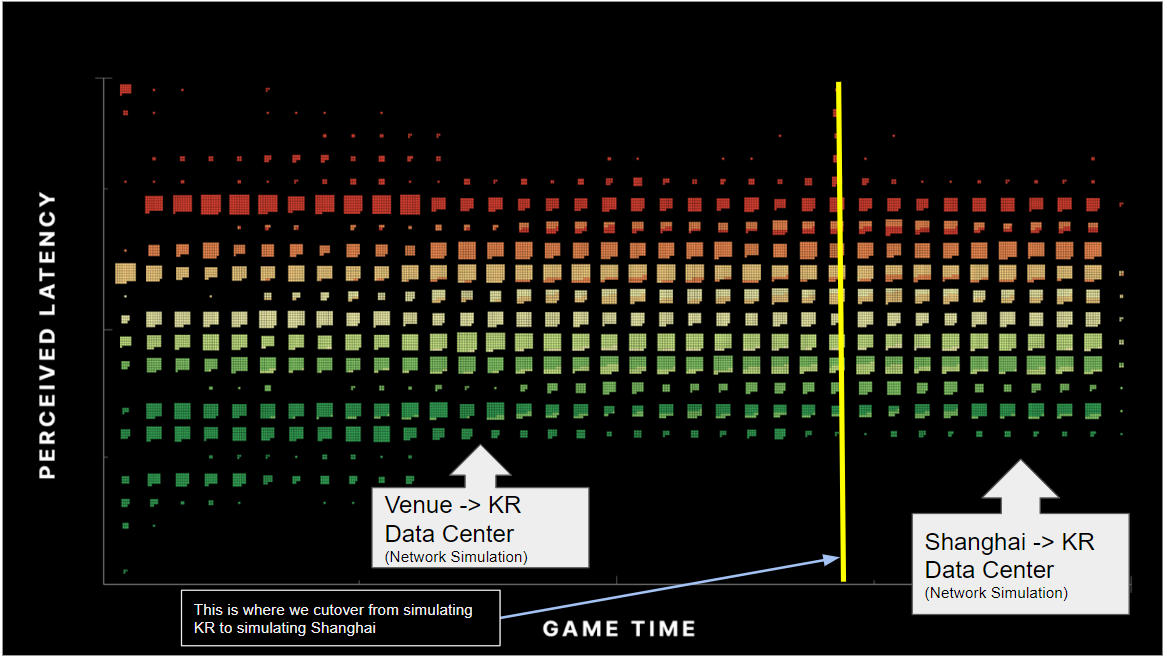
As with the previous two experiments, we first started out simulating a low ping environment, and then adjusted after a couple of minutes to simulate a higher ping environment. But unlike the previous experiments, after deploying the configuration change the Latency Service was compensating correctly. The graph was showing that the latency was indistinguishable even after switching from low ping to higher ping.
**Problem solved, right?**
While the configuration change was correcting for a bug in the ping calculation in the game, one side effect was that after posting the change the on-screen (ctl-v) overlay that shows FPS and ping would show an incorrect number for the players in the Busan venue such that the number on screen would be lower by about 13 ms than the actual latency. This is because the configuration change we made to the Latency Service essentially added an offset to the target value to compensate for the calculation bug. This had a down-stream effect of applying an offset to the logged and displayed ping values in the client (more on this later). The result is that the displayed numbers would be lower than the real ping by 13 ms. While this is unfortunate, we felt it was better to have the right latency added to the game for a level playing field, even if it meant that the wrong value would be displayed on screen.
The path forward, and a difficult realization
---------------------------------------------
Once we identified a way to properly measure real latency and had identified a way to alter the configuration to compensate for this calculation error, we immediately started prepping a plan to deploy the fix and communicate to the players and the community what had happened.
As we understood the problem better, we also came to a very difficult realization.
What we realized is that the players in the MSI venue were playing on ping that was worse than 35 ms, while the remote team in Shanghai was playing at the desired 35 ms ping range - which is the natural latency between Shanghai and Busan - we had not achieved the ping parity required for fair play.
We needed to tell the teams immediately. The only open question was whether the difference was significant enough to require that the games be replayed. This would be a Competitive Operations call. Our estimations put the latency disparity somewhere in the 15-20 ms range, which drove the difficult decision to remake the three impacted games with the new configuration change to ensure competitive integrity.
Making sense of the ping overlay numbers
----------------------------------------
Once we had made the decision to remake the impacted games from earlier in the tournament, we knew we had a lot of work to do. This meant re-working schedules and reaching out to teams to make sure they understood what was going on and why. It also meant prepping a config change to the game servers and re-running all of the tests to verify that the change had gone through. We also asked the pros to come to the venue to test the servers with the new configuration just to double and triple check that we had addressed the issue. We even did blind tests where we asked some of the pros to try both configurations and let us know which one felt like 35 ms ping and which felt like it was more than that.
Unfortunately, one step that we missed was communicating clearly to the players, fans, and the broadcast team the fact that the ping overlay numbers were incorrect.
It was not long after the tournament re-commenced that our fans started pointing out what seemed to be an unfair advantage for the teams in Busan. We started seeing fans posting screenshots from our broadcast showing 22ms ping, instead of the ~35 ms ping that was expected.

This is clearly something that we have to explain.
As mentioned earlier, the work-around for the bug in the Latency Service was a compensation offset value added to the configuration. This offset had a side effect on the values shown in the on-screen overlay:
- The ping numbers displayed for the players in Shanghai are **correct**
- The ping numbers displayed for players in Busan are **incorrect;** in actuality, the real game play latency is roughly 13 ms higher than what is displayed
To reiterate the reasons for this, in Shanghai the ping numbers are correct because they are already at the latency target of 35 ms, so no compensation was added to their experience. The reason the Busan numbers are incorrect is that latency configuration offset corrected the ping miscalculation in the engine so the real ping would be equalized to ~35 ms, but this had the downstream effect of offsetting the logs and the onscreen display of the ping by about 13 ms.
To verify this, we gathered client logs from 30+ sessions and graphed the ping/latency data that correlates to what the players would have seen in the on screen display.
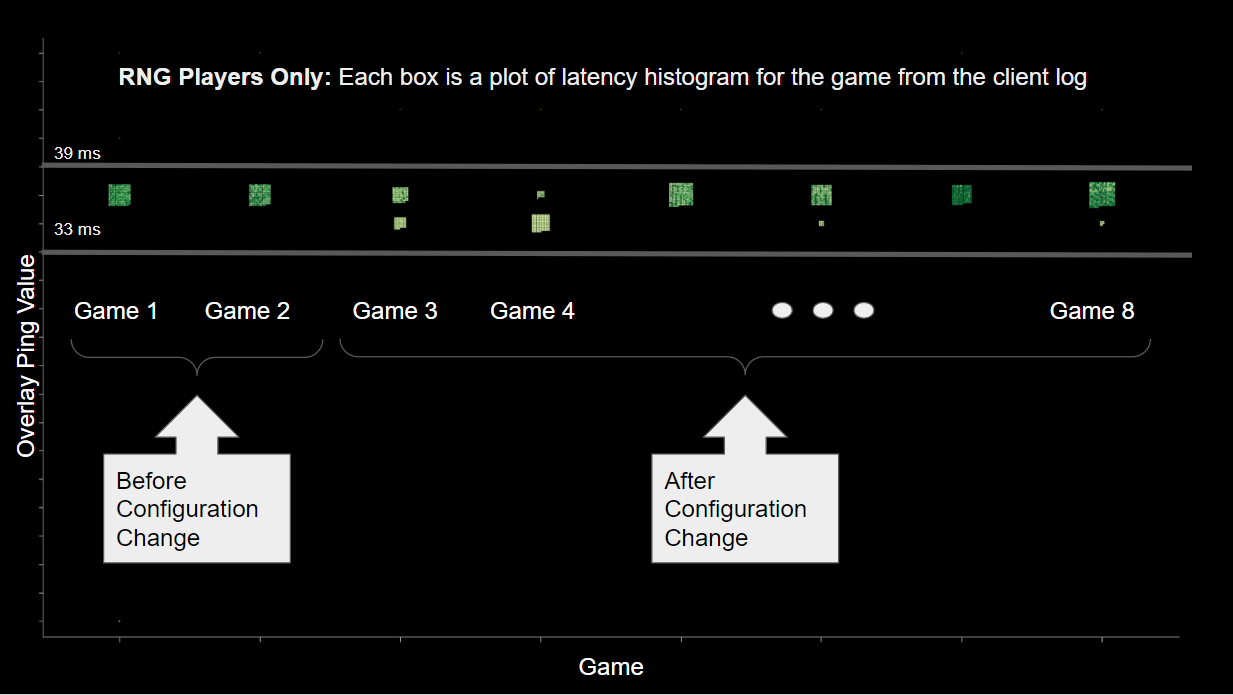
In the graph above, we are showing only games from RNG. The Y-axis is the ping value reported. Unlike the graphs from the previous section that showed data over time, in this case the X-axis represents discrete sets of data, one for each game. So each of the green squares is a histogram plot of the reported ping value, as read from the client logs, for one player’s machine for one game. As you can see, there is some minimal fluctuation in the values and the values are all in the range between 33 ms and 39 ms. This fits the known natural ping value of 35ms +/- 5ms for RNG.
The next data set we looked at is the client logs from the players in Busan both before the configuration change and after the configuration change.
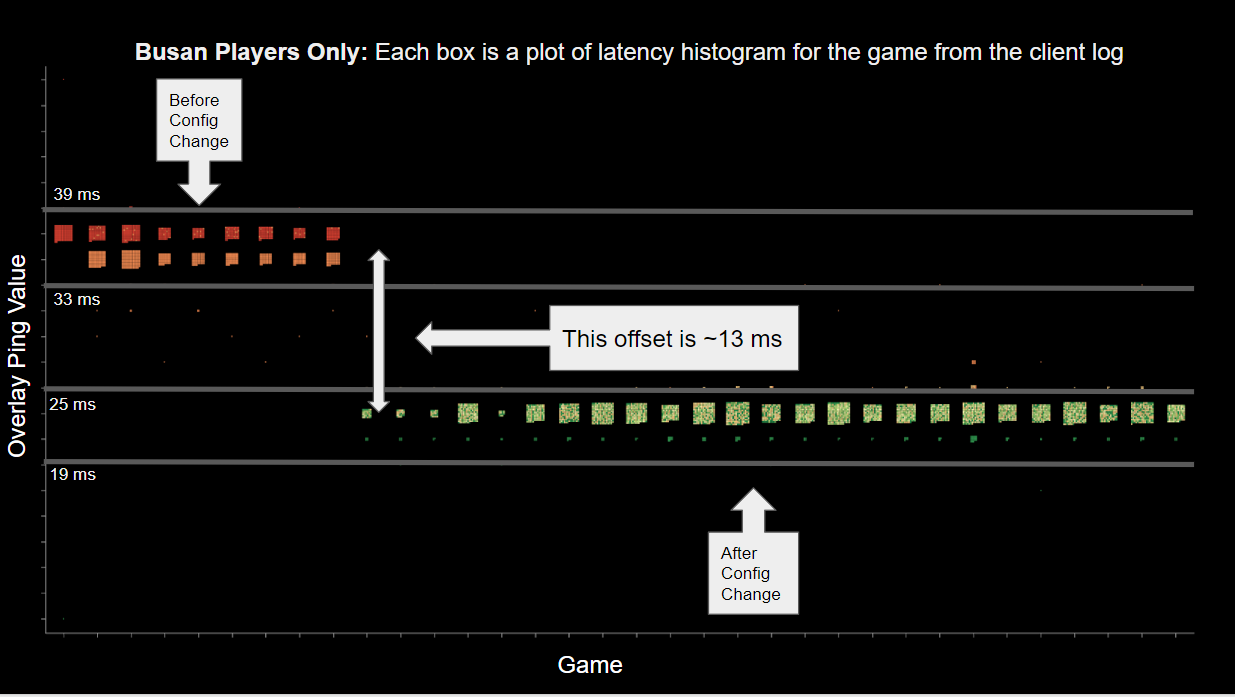
In the graph above, we have filtered the data to only show games played from the Busan venue. The games shown on the left of the double-sided arrow are the ones played before the configuration change. As you can see, the reported values are between 33 and 39 ms, which are in the range of 35 ms +/- 5. We also know that these values are **incorrect** based on the player reports that it felt wrong which we subsequently verified with our updated end-to-end monitoring tool.
On the right side, you can see that after we applied the configuration change that fixed the **real** ping, the **reported** ping value went down, showing values between 19 ms and 25 ms and generally in the range of 22ms +/- 5ms. By subtracting these two values we can see that the offset error in the reported ping value is consistent, and it is approximately 13ms (35ms - 22ms = 13ms). So after the configuration change to address the real latency, when the overlay ping value on a player screen in Busan shows 22 ms, in reality the correct value should be 35 ms.
Going back to the screen shot showing the T1 vs. SGB game, this explains why Zeus’s screen showed 22 ms even though we had equalized the real ping through the configuration change to 35 ms across the board. If we add the corrective offset value of 13 ms, which we gathered from empirical data from the client logs, we get the correct ping value of 35ms.
Conclusion
----------
As a technology team supporting live events, we do everything we can to test, check, double check and triple check the competitive environment to ensure an issue-free experience. Striving to create a level playing field for pro teams will always be a top priority. Our goal is to have the tech get out of the way and have the sport and the gameplay take center stage.
Our team is dedicated to upholding competitive integrity, and works hard to create the best esports viewing experience to fans around the world. Any changes to plans involve risk, but we do our best to plan and navigate those risks with the goal of creating the best experiences for the teams and fans.
In this case, there was a bug that we missed which impacted the games. We sincerely apologize for the disruption and frustration caused during the tournament, as well as the confusion caused by the unclear communication around the issue with incorrect values on the ping overlay.
We know this hasn’t been easy, and we are working on additional testing and verification measures to ensure we have smooth Rumble and Knockout stages. We would like to recognize the pro teams and players for their resilience throughout the competition, despite these hurdles, and thank them for the feedback that helped us to resolve these issues. While we can’t say that there will never be a bug again that impacts competition in the future, we can commit to learning from this, getting better, communicating more proactively with teams and fans, and continuing to invest in improving our ability to monitor and verify environments for our events.

